Subscribe to AI newsletter
Your data is complely secured with us. We don't share with anyone.
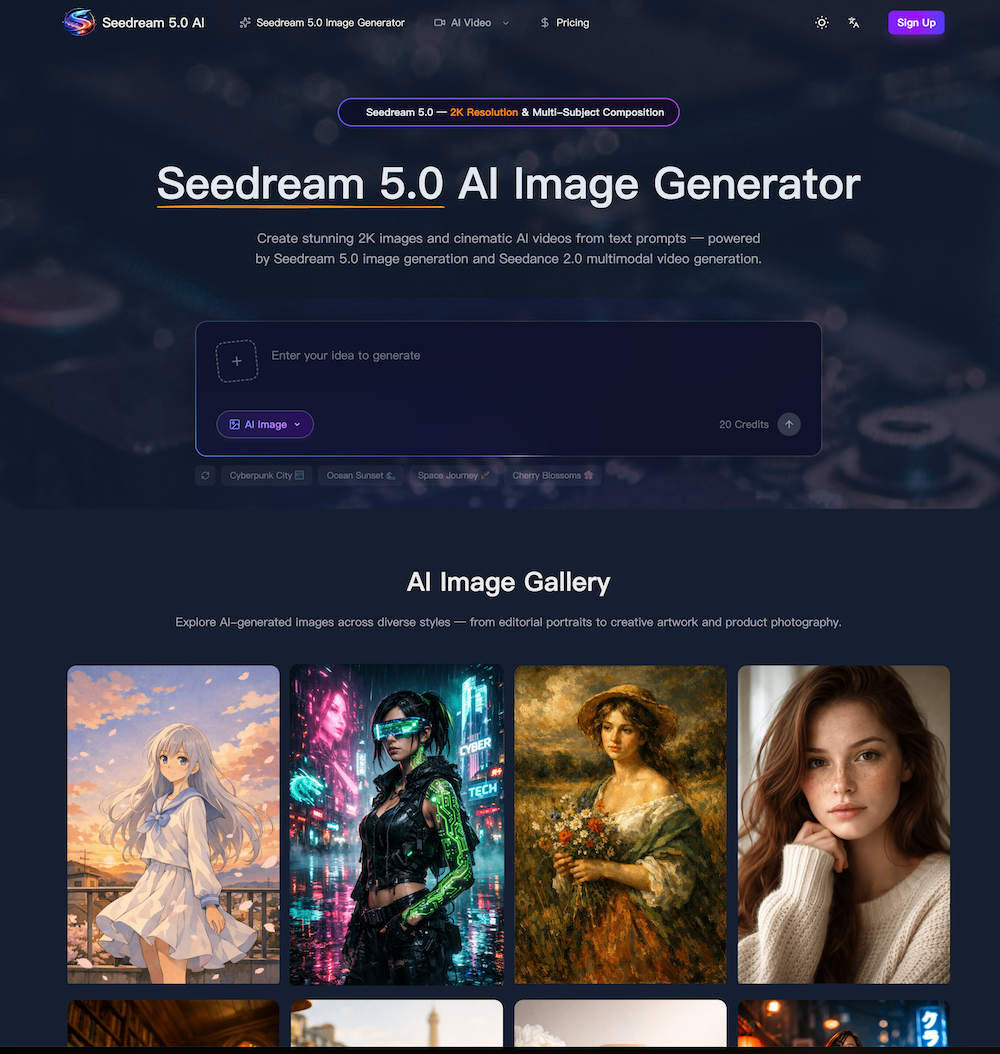
This is a fifth-generation diffusion transformer model that handles both image and video generation. It produces visuals at up to 2K resolution from text prompts or reference media. The model covers text-to-image, image-to-image editing, text-to-video, image-to-video, and motion control — all within a single workflow. It is built for creators, designers, marketers, and e-commerce teams who need studio-quality content without manual post-production.
Core capabilities include 2K image generation with photorealistic detail, Seedance 2.0 cinematic video output with synchronized audio, advanced prompt understanding that handles spatial layout and lighting, multi-subject composition for three or more characters, native style control across ten-plus visual styles, and natural-language image editing. Seedance 2.0 video generation supports durations from three to fifteen seconds. Images can be output in PNG, JPEG, or WebP at custom aspect ratios.
Independent benchmarks show competitive or superior results compared to DALL-E 3, Midjourney, and Stable Diffusion XL in prompt adherence, photorealism, and multi-subject accuracy. Inference runs roughly forty percent faster while maintaining 2K output. For video, Seedance 2.0 produces cinematic clips with lip-sync audio, competing with Runway Gen-3 and Pika in visual fidelity and temporal coherence.
You provide a text prompt or upload a reference image, then select Seedance 2.0 as your model, set duration, aspect ratio, and whether to include audio. Seedance 2.0 generates a cinematic video clip in the cloud and returns a downloadable MP4. Text-to-video mode creates entirely new footage from a description. Image-to-video mode animates a still image based on your prompt. Motion control mode transfers movement from a reference video onto a character image.
Seedance 2.0 video output ranges from three to fifteen seconds. Supported aspect ratios include 16:9, 9:16, and 1:1. Resolution goes up to 2K. Audio generation is available and adds synchronized dialogue or ambient sound. The Seedance 2.0 motion control mode accepts reference videos between three and thirty seconds and outputs at 720p or 1080p.
Images generate at up to 2K resolution (2048×2048 pixels). Supported aspect ratios are 1:1, 4:3, 3:4, 16:9, 9:16, and 21:9 — plus custom dimensions rounded to the nearest 32 pixels. Output formats include PNG, JPEG, and WebP. Prompts support up to 5,000 characters, giving you room for detailed scene descriptions, style references, and lighting instructions.
Yes. New accounts receive free credits to explore both image and video generation. Image generation starts from three credits per image; video costs vary by model and duration, starting from twenty-five credits for short clips. If you need more capacity, one-time credit packs and subscription plans are available with savings up to fifty percent off the standard rate.
Yes. All generated images and videos are cleared for commercial use including advertising, social media, product marketing, editorial content, and print. There are no royalty fees or per-use charges beyond the initial credit cost. Outputs belong to you, so you can edit, redistribute, or incorporate them into client deliverables without additional licensing.
Upload an existing image and describe the changes you want in natural language. The model preserves overall composition while applying targeted edits — style transfer, object removal, background replacement, color grading, or detail enhancement. You can also upload reference images for guided style transfer, letting the model blend source content with a target aesthetic while keeping the original structure intact.
The model supports photorealism, anime, cyberpunk, watercolor, oil painting, 3D rendering, minimalist illustration, cinematic color grading, and vintage photography. Style is controlled through text prompts or by uploading a reference image. You can combine multiple style keywords in a single prompt — for example, cinematic lighting with watercolor textures — to create unique hybrid aesthetics.
A single 2K image typically completes in five to ten seconds. Video generation takes thirty seconds to several minutes depending on duration and model complexity. The architecture runs roughly forty percent faster than previous versions and supports batch image generation when multiple outputs are needed from the same prompt.
Yes. For image generation, you can upload reference images for style transfer, editing, or guided composition. For video generation, image-to-video mode accepts a start frame (and optional end frame) to control the animation arc. Motion control mode accepts a reference video to transfer body movement onto a character image. Supported formats include PNG, JPEG, WebP for images and MP4, MOV, WebM for video.
Yes. The generator works on Chrome, Safari, Firefox, and Edge across desktop, tablet, and mobile devices. All rendering happens in the cloud, so your device only needs a stable internet connection. The responsive interface adapts to smaller screens with a collapsible sidebar and touch-friendly controls for prompt editing, media upload, and video playback.
Start with the main subject, then layer in environment, lighting, camera angle, and artistic style. Use commas to separate concepts rather than writing long compound sentences. For multi-subject scenes, describe each character individually before specifying their interaction. Terms like 'cinematic lighting,' 'shallow depth of field,' or 'golden hour' consistently improve image quality. For video prompts, describe motion and camera movement explicitly — for example, 'slow zoom in' or 'tracking shot following the subject from left to right.'
Create a free account to receive starter credits immediately. From the dashboard, choose the image generator or video generator tab. Type a text prompt describing the visual you need, then adjust optional settings like aspect ratio, style, duration, and audio. Click generate and the model processes your request in the cloud. Images arrive within seconds; videos complete within a few minutes. Download the output directly, or adjust your prompt and re-generate to refine the result further.
Yes. The generator excels at product photography thanks to precise control over lighting, background, and composition. Upload a product photo and describe the desired setting — marble surface, lifestyle scene, or transparent background — and the model renders a professional result. Many e-commerce teams rely on this workflow to produce consistent catalog imagery across hundreds of SKUs without booking a physical photo studio, cutting production time from days to minutes.
This next-generation platform represents a highly advanced AI tool that pushes the boundaries of modern Image Generation by combining both image and video creation into a single, unified workflow. Built on a fifth-generation diffusion transformer model, the system is capable of producing stunning 2K visuals with photorealistic detail, accurate lighting, and consistent composition. Unlike traditional tools that specialize in only one function, this AI tool integrates text-to-image, image-to-image editing, text-to-video, and even motion control, making it a comprehensive solution for creators, marketers, and e-commerce teams.
One of the most compelling aspects of this AI tool is its feature depth. The Image Generation capabilities are particularly strong, offering high-resolution outputs (up to 2048×2048) across multiple formats such as PNG, JPEG, and WebP. Its advanced prompt understanding allows users to define complex scenes with multiple subjects, spatial relationships, and stylistic elements—all processed accurately in a single pass. This significantly reduces iteration time and enhances creative efficiency. Additionally, native style control enables seamless switching between photorealism, anime, watercolor, cyberpunk, and more, giving users full creative flexibility.
Compared to other leading AI tools in the Image Generation space, this platform demonstrates clear advantages in speed and precision. Benchmarks indicate faster inference times—up to 40% quicker—while maintaining superior prompt adherence and multi-subject accuracy. This performance edge is particularly valuable for professionals who need to generate large volumes of content quickly without compromising quality.
Another standout feature is its natural-language image editing. Users can upload existing visuals and simply describe the desired changes, such as background replacement or style transformation, and the AI tool executes them with precision. This intuitive workflow lowers the barrier for non-experts while still meeting professional standards.
Overall, this AI tool delivers a powerful combination of speed, quality, and versatility in Image Generation. By unifying multiple creative processes into one platform and offering studio-grade outputs, it provides a scalable solution for modern content production, from marketing campaigns to product photography and beyond.


Flux 2 Max represents the most advanced release in the Flux 2 lineup, designed for creators who demand precision, realism, and production-ready visual output. As both a high-end AI Image Generator and a powerful AI Image Editor, Flux 2 Max pushes visual quality and consistency to a new level, making it suitable for professional creative workflows.

In this digital age, AI image generation tools are sparking an unprecedented creative revolution.Today, we delve into the mechanics of AI image generation, explore its underlying technology, and guide you in creating your own AI artwork!

This comprehensive guide explores the best AI image generators available in 2026, highlighting their unique features, strengths, and ideal use cases. We'll dive deep into each tool's capabilities to help you identify which AI image generator best suits your creative needs.