Subscribe to AI newsletter
Your data is complely secured with us. We don't share with anyone.
Flux is an Amazing AI models from the Black Forest.

State-of-the-art image generation with top of the line prompt following, visual quality, image detail and output diversity.
We release the FLUX.1 suite of text-to-image models that define a new state-of-the-art in image detail, prompt adherence, style diversity and scene complexity for text-to-image synthesis.
All public FLUX.1 models are based on a hybrid architecture of multimodal and parallel diffusion transformer blocks and scaled to 12B parameters. We improve over previous state-of-the-art diffusion models by building on flow matching, a general and conceptually simple method for training generative models, which includes diffusion as a special case. In addition, we increase model performance and improve hardware efficiency by incorporating rotary positional embeddings and parallel attention layers. We will publish a more detailed tech report in the near future.
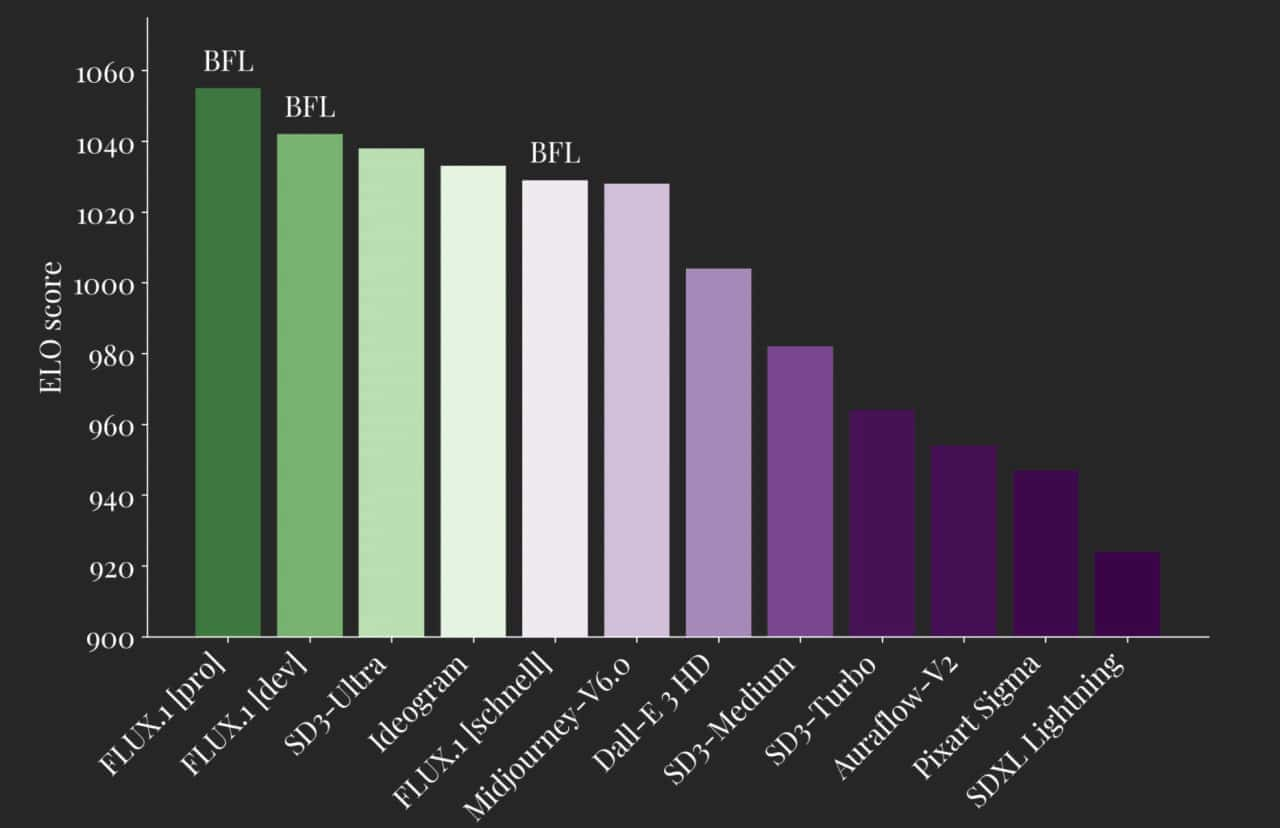
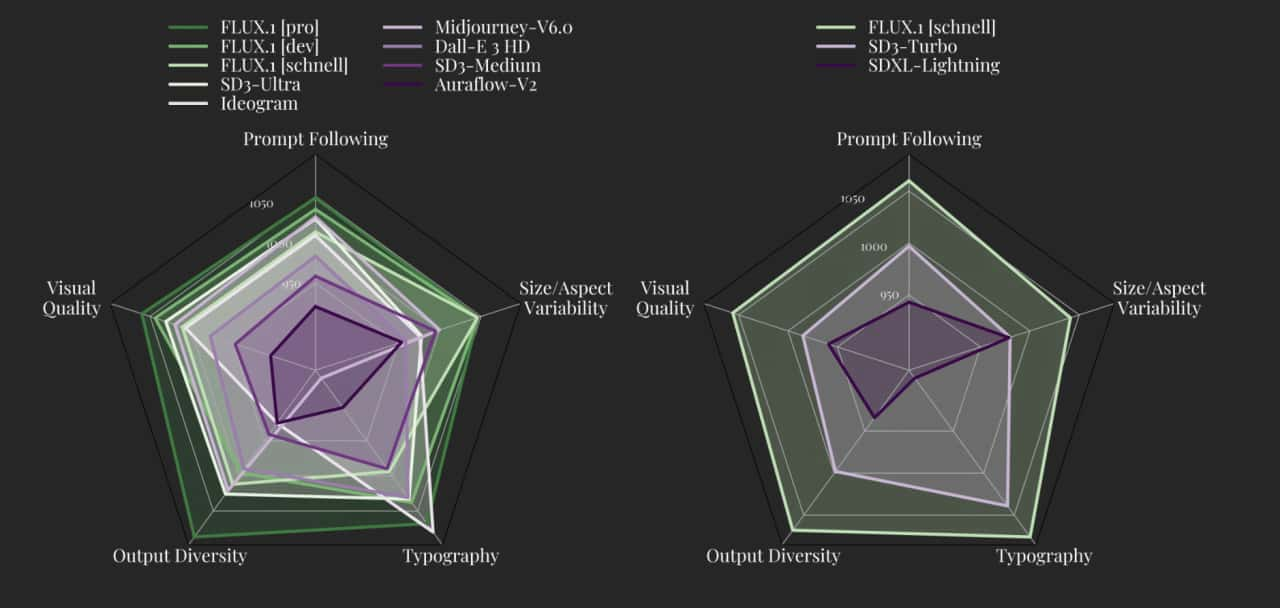
FLUX.1 defines the new state-of-the-art in image synthesis. Our models set new standards in their respective model class. FLUX.1 [pro] and [dev] surpass popular models like Midjourney v6.0, DALL·E 3 (HD) and SD3-Ultra in each of the following aspects: Visual Quality, Prompt Following, Size/Aspect Variability, Typography and Output Diversity. FLUX.1 [schnell] is the most advanced few-step model to date, outperforming not even its in-class competitors but also strong non-distilled models like Midjourney v6.0 and DALL·E 3 (HD) . Our models are specifically finetuned to preserve the entire output diversity from pretraining. Compared to the current state-of-the-art they offer drastically improved possibilities as shown below
All FLUX.1 model variants support a diverse range of aspect ratios and resolutions in 0.1 and 2.0 megapixels, as shown in the following example.
Today we release the FLUX.1 text-to-image model suite. With their strong creative capabilities, these models serve as a powerful foundation for our upcoming suite of competitive generative text-to-video systems. Our video models will unlock precise creation and editing at high definition and unprecedented speed. We are committed to continue pioneering the future of generative media.

prompt: an old piano in my living room

prompt:detailed cinematic dof render of an old dusty detailed CRT monitor on a wooden desk in a dim room with items around, messy dirty room. On the screen are the letters “FLUX” glowing softly. High detail hard surface render

prompt:a portal into a mythical forest on the wall of my small messy bedroom
We offer FLUX.1 in 3 distinct variants
The best of FLUX.1, offering state-of-the-art performance image generation with top of the line prompt following, visual quality, image detail and output diversity. We are slowly ramping up our inference compute for FLUX.1 [pro] in our API. Moreover FLUX.1 [pro] can be accessed via our Partners Replicate and fal.ai. We also offer dedicated and customized enterprise solutions – reach out via flux@blackforestlabs.ai to get in touch.
FLUX.1 [dev] is an open-weight, guidance-distilled model for non-commercial applications. Directly distilled from FLUX.1 [pro], FLUX.1 [dev] obtains similar quality and prompt adherence capabilities, while being more efficient than a standard model of the same size. FLUX.1 [dev] weights are available on HuggingFace and can be directly tried out on Replicate or fal.ai. For applications in commercial contexts, get in touch out via flux@blackforestlabs.ai.
Our fastest model is tailored for local development and personal use. FLUX.1 [schnell] is openly available under an Apache2.0 license. Similar, FLUX.1 [dev], weights are available on Hugging Face and inference code can be found on GitHub. FLUX.1 [schnell] is also available via Replicate and fal.ai.
We are happy to partner with Replicate and FAL. You can sample our models using their services. Below we list relevant links.
Replicate:
FAL:
Github
https://github.com/black-forest-labs/flux?tab=readme-ov-file
Twitter users experiences and reviews of Flux 1 AI. Their firsthand experiences and feedback provide insights into the advantages and features of this AI tool, helping you better understand it.

Transform your photos with AI filters into anime, clay, 3D, pixel, emoji, video game, sticker, and more styles
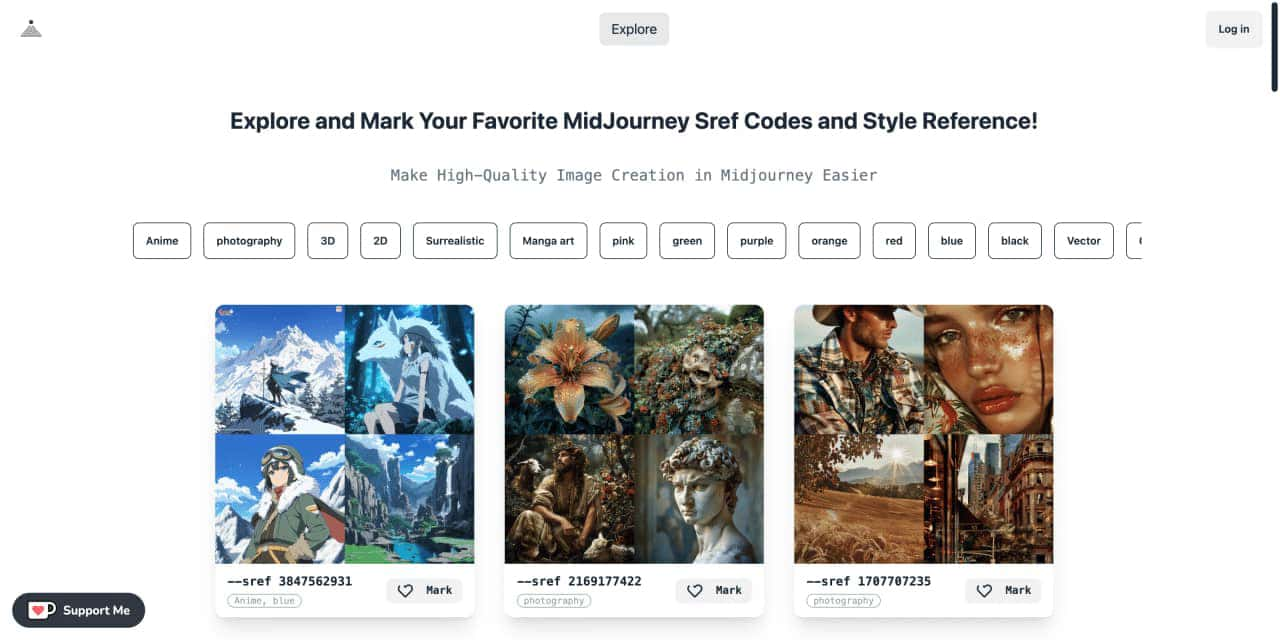
Explore a list of 181 unique midJourney sref code and style references to find your perfect MidJourney sref code effect.
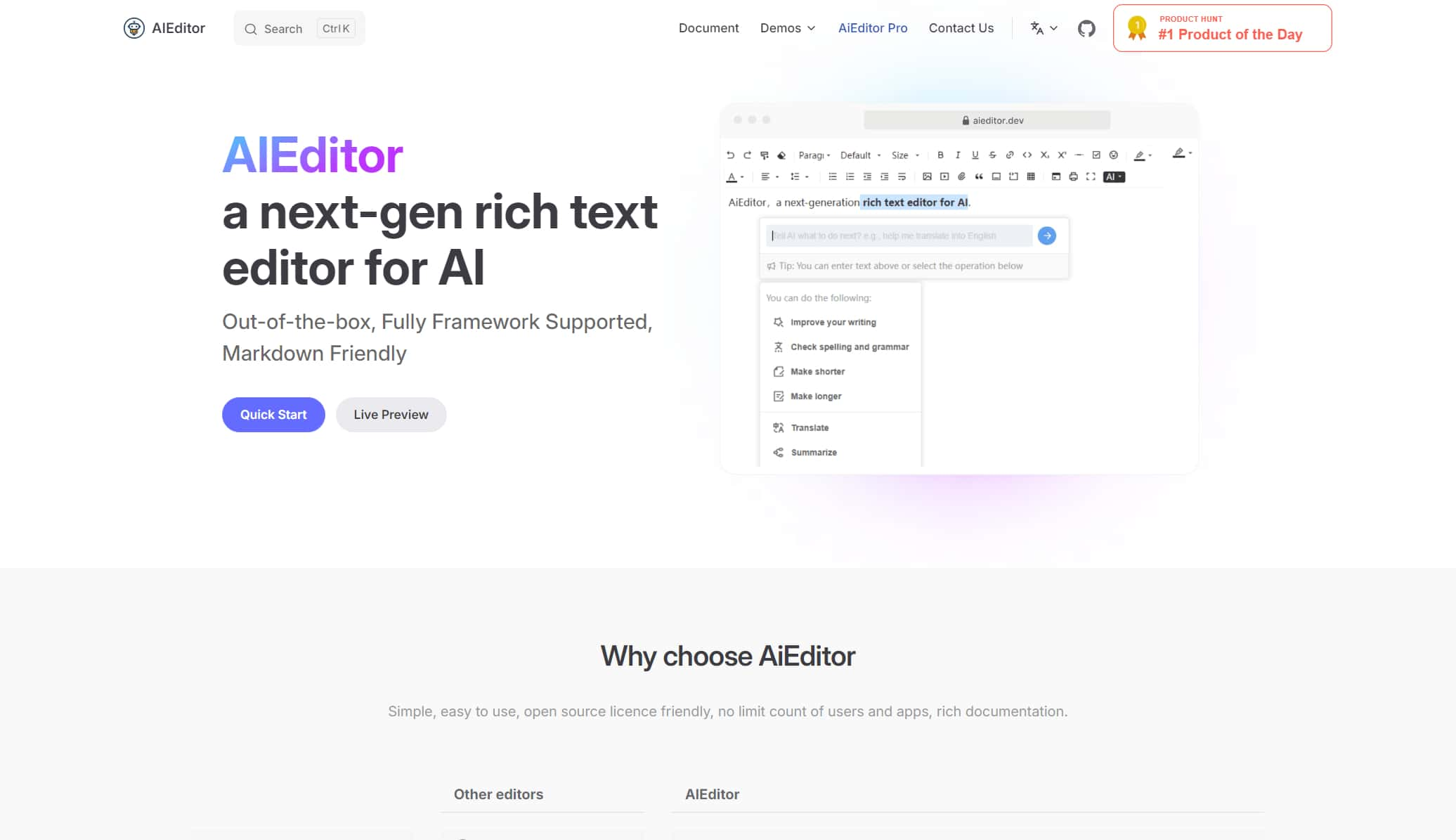
A next-generation rich text editor for AI, open-source rich text editor, modern rich text editor
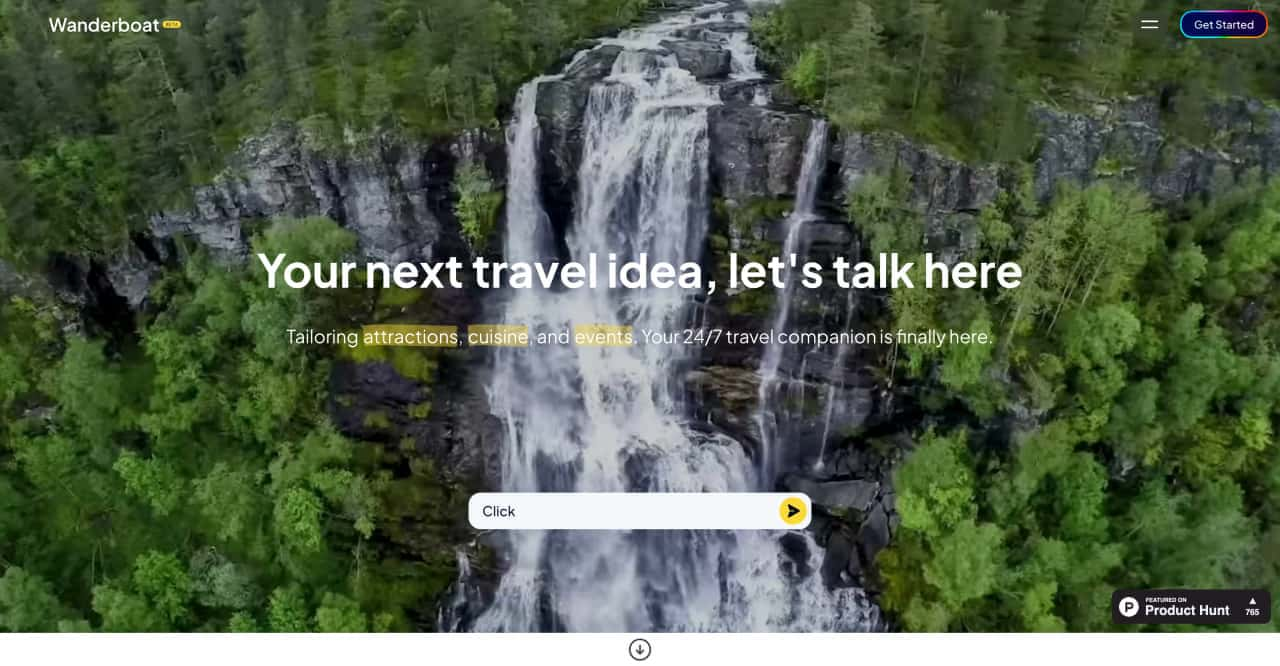
Your next travel idea, let's talk here. Plan your travel with AI. Discover what to do on your upcoming vacation. Find things to eat in the most popular destinations in the world.


Flux 2 Max represents the most advanced release in the Flux 2 lineup, designed for creators who demand precision, realism, and production-ready visual output. As both a high-end AI Image Generator and a powerful AI Image Editor, Flux 2 Max pushes visual quality and consistency to a new level, making it suitable for professional creative workflows.

In this digital age, AI image generation tools are sparking an unprecedented creative revolution.Today, we delve into the mechanics of AI image generation, explore its underlying technology, and guide you in creating your own AI artwork!

This comprehensive guide explores the best AI image generators available in 2026, highlighting their unique features, strengths, and ideal use cases. We'll dive deep into each tool's capabilities to help you identify which AI image generator best suits your creative needs.