
2025年最佳AI大模型与AI工具
2025年最佳AI大模型与AI工具,最受欢迎的免费AI大模型与AI工具。
An interactive demo for developers to try the new text-to-speech model in the OpenAI API
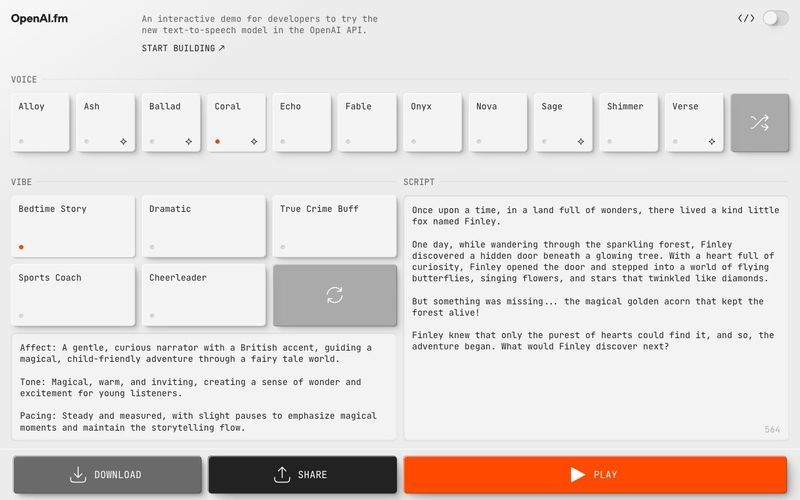
探索 OpenAI API 中的音频和语音功能。
复制页面
OpenAI API 提供了一系列音频功能。如果您已经知道要构建的内容,可以在下方找到相应的使用案例开始开发。如果您不确定从哪里开始,可以阅读本页面的概述。
LLM(大语言模型)可以通过声音输入处理音频,生成声音输出,或两者兼具。OpenAI 提供多个 API 端点,帮助您构建音频应用程序或语音代理。
语音代理可以理解音频,以处理任务并以自然语言响应。有两种主要方式实现语音代理:使用语音到语音模型和 Realtime API,或者通过组合语音到文本模型、文本语言模型(用于处理请求)以及文本到语音模型来实现。语音到语音方法延迟更低,更加自然,而组合多个模型的方法则是将文本代理扩展为语音代理的可靠方式。
实时处理音频,以构建语音代理和其他低延迟应用程序,包括转录功能。您可以使用 Realtime API 在模型内外进行音频流式传输。我们的高级语音模型提供自动语音识别功能,以提高准确性、降低延迟,并支持多语言交互。
要将文本转换为语音,可以使用 Audio API audio/speech 端点。与该端点兼容的模型包括 gpt-4o-mini-tts、tts-1 和 tts-1-hd。使用 gpt-4o-mini-tts,您可以让模型以特定方式或特定语调进行发声。
要将语音转换为文本,可以使用 Audio API audio/transcriptions 端点。与该端点兼容的模型包括 gpt-4o-transcribe、gpt-4o-mini-transcribe 和 whisper-1。通过流式传输,您可以持续输入音频,并获得连续的文本输出。
用于转录或生成音频的 API 主要包括:
API支持的模式流式支持Realtime API音频和文本输入输出支持音频流式输入和输出Chat Completions API音频和文本输入输出支持音频流式输出Transcription API音频输入支持音频流式输出Speech API文本输入和音频输出支持音频流式输出
主要区别在于通用 API 和专用 API。使用 Realtime 和 Chat Completions API,您可以利用最新模型的音频理解和生成能力,并结合其他功能(如函数调用)。这些 API 适用于广泛的使用场景,且您可以选择不同的模型。
另一方面,Transcription、Translation 和 Speech API 仅限于特定的任务,例如语音转录、翻译或语音合成。
选择合适 API 的另一种方式是考虑您需要多少控制权。如果您希望设计对话交互,即模型能够思考并用语音响应,可以使用 Realtime 或 Chat Completions API,具体取决于您是否需要低延迟。
使用这些 API,您无法提前确定模型的具体回答,但能提供更自然的交互体验。
如果您希望更多控制和可预测性,可以使用语音到文本 / LLM / 文本到语音的模式,以确保模型输出可控,但会增加一定的延迟。
Audio API 适用于此类场景:结合 LLM 与 audio/transcriptions 和 audio/speech 端点,接收用户语音输入,处理生成文本响应,再转换为语音输出。
如果需要 实时交互 或 转录功能,请使用 Realtime API。
如果实时性不是必须,但希望构建 语音代理 或支持 函数调用 的音频应用,请使用 Chat Completions API。
如果仅需特定用途,请使用 Transcription、Translation 或 Speech API。
GPT-4o 和 GPT-4o mini 等模型原生支持多模态输入输出,即可以理解和生成多种格式的数据。
如果您的应用当前使用 Chat Completions 端点进行文本交互,可考虑添加音频功能。例如,如果您的聊天应用支持文本输入,可以增加音频输入和输出——只需在 modalities 数组中包含 audio 并使用音频模型,如 gpt-4o-audio-preview。

Convert text to speech online for free with our AI voice generator. Create natural AI voices instantly in any language - perfect for video creators, developers, and businesses.
Tiktok voice is an Ai powered tts ,text to speech generator tool. Can generate lady's voice, Siri-like voice ,the other poupular and vrial tiktok voices
Transform your content with cutting-edge AI voice over and text to speech solutions. Our Voice Design AI offers natural-sounding, customizable voices for podcasts, e-learning, and more. Try our AI voice generator today!
2025年最佳AI大模型与AI工具,最受欢迎的免费AI大模型与AI工具。

探索10个强大的AI写作工具,它们将彻底改变你的内容营销工作流程。从演示文稿到文章,这些工具可以帮助你高效创建引人入胜的内容。
All in AI Tools website Update log
With the launch of the iOS 18.1 Beta version, registered developers can now experience some of the features of Apple AI, a cutting-edge addition to AI tools.